

Author: Sarikonda Grishmanth Reddy
Mentor: Dr. Eric Fouh
DRS International School
This paper explores the implementation of a softmax classifier for image classification tasks using the CIFAR-10 dataset. The methodology involves using TensorFlow to develop a simple classification pipeline that learns to categorize images into ten classes. Key findings show that the classifier achieved a training accuracy of 43% and a test accuracy of 26.5%, indicating the limitations of the softmax model for complex visual tasks. Despite performance limitations, the project highlights fundamental processes in image classification and suggests pathways for further research using more advanced architectures.
Image classification, a core application of neural networks, provides independent visual data categorization, making it crucial for a wide range of applications . It converts photos into actionable information, improving decision-making and the effectiveness of healthcare, security, and autonomous systems. This paper details my experience developing and applying a softmax classifier to an image classification task. Here, I highlight the main takeaways and difficulties that emerged while considering areas that may benefit from improvement. In addition to shedding light on the subtler parts of algorithm creation in computer vision, this work should present readers with practical aspects of developing and refining models for image classification through hands-on experiences and technical considerations.
1. Motivation
The purpose of image recognition, a branch of computer vision, is for presenting robots a way to categorize and comprehend visual data. It’s largely tied to deep learning methods that successfully imitate particular features of human vision [2]. Image recognition mostly involves sophisticated mathematical models to classify and segment pictures, integrating visual data into organized information [3]. Applications where visual data analysis is essential, like automated healthcare diagnostics, autonomous vehicle navigation, and pattern recognition in security systems, make the transformation in question crucial. Using machine learning methods for image identification, highly precise classifications are found that form the basis of artificial intelligence for identifying hierarchical spatial relationships and relational patterns in pictures [4, 5].
Across many scientific and industrial fields, image recognition is vital. In healthcare, image recognition analyzes MRI, CT, and X-ray imagery to assist with diagnosing diseases [1]. These systems use neural networks that were earlier taught to identify anatomical features and spot anomalies, which helps radiologists and other medical professionals identify and diagnose diseases early [6]. Biometric identification in security systems relies heavily on picture recognition, particularly in technology for facial recognition, where computers examine facial features to confirm an individual’s identity [5]. In real-time recognition of images, it is essential for autonomous cars because it can identify and categorize road objects including lanes, obstructions, and pedestrians to direct the vehicle’s reaction [5]. Such uses of image recognition allow for safer and more effective solutions in a variety of companies while also advancing technical capabilities [1].
1.1 Deep Learning Advancements in Image Recognition
Deep learning algorithms, particularly convolutional neural networks (CNNs), have been the main driver of image recognition advancements [7]. CNNs are made up of layers of convolution that apply filters to images, enabling neural networks to detect low-level characteristics like edges and textures before moving on to more complex patterns and objects [7]. One prevalent variation of CNN is called region-based CNN (RCNN), and it seems to have made object identification much more efficient in that it first distinguishes areas of interest before using its CNNs to identify objects within those regions [8]. Other notable strengths include its adaptability to handle various object detection and segmentation tasks, such as in security surveillance and medical imaging [8]. Another significant model is the You Only Look Once (YOLO) architecture, which is ideal for real-time applications because object detection only makes one pass through the entire image grid [9].
1.2 Vision Transformers and Emerging Techniques
Vision transformers (ViTs) are a recent development in image recognition [1]. Originally intended for natural language processing, transformers employ self-attention processes to discover interactions in visual data [1]. By removing the spatial constraints imposed by CNNs, this technique allows the model to “look at” significant areas of an image and enables a method that outperforms CNNs and others in collecting global context inside photographs [1]. While training on huge datasets, it can perform similarly to CNN or even better in some cases [1].
1.3 Challenges and Ethical Considerations
Despite ethical and scientific obstacles, image recognition technology has advanced tremendously. In computer vision, this is basically the result of generalization; in highly controlled conditions, most models are unable to replicate variations in illumination, perspective, and occlusion [10]. Finally, training complex models requires enormous quantities of data and processing power, which makes scaling extremely difficult in contexts with limited resources [10]. There are ethical concerns as well, particularly with regard to face recognition technology, which has difficulties with algorithmic bias, privacy, and data security [10]. Social concerns about the use of AI in sensitive areas may arise from bias in training sets, which may provide discriminatory results, especially when algorithms perform poorly for specific demographic groups [10].
1.4 Future Directions in Image Recognition Research
It is likely that future image recognition research will focus on learning algorithms that work better with less supervised examples using methods like semi-supervised and unsupervised learning [11]. We will investigate techniques like Generative Adversarial Networks (GANs) for creating realistic training data in order to address the issue of scarce data and strengthen models [11]. To put it briefly, image recognition is the state-of-the-art in AI research, using scientific advancements to enable machines to understand the visual world and providing enormous transformational potential in a variety of scientific and industrial applications.
2. Implementation
One of the key elements of picture classification models and much more crucial for deep learning architectures is the softmax classifier, which carries out the last activation function, which converts neural network outputs into probability distributions across several classes. The softmax function may be expressed mathematically as taking the exponential numbers of each significance, or “logit,” that emerges from the final segment of the network and normalizing them by adding them together. The outputs are successfully scaled to provide a probability distribution that may be used for multi-class classification since the probabilities of each class sum up to one. The softmax classifier gives a probability to each potential class for every given input picture, with the highest possibility denoting its forecast of the model for the most likely class.
When it came to providing a stochastic understanding for the output that would be helpful in measuring the model’s confidence, the softmax classifier proved to be highly helpful to the models, particularly those trained on multi-class datasets like CIFAR-10[2] or ImageNet. In order to quantify the distinction between the predicted and true probability distributions (instantaneous matrix for the true label), softmax is employed in conjunction with a loss of cross entropy during training. This indicates that by iteratively lowering the loss, the model increases its classification accuracy. The majority of typical image classification tasks are successfully completed by softmax classifiers, however they might perform appallingly when inputs are unclear or classes overlap. Therefore, thermo scaling or other calibration techniques are occasionally used in order to make the output distributions from softmax less confident and more interpretable in real-world applications.
Specifically designed to train artificial intelligence models on classification of images problems, CIFAR-10[2] has become one of the most widely used benchmarking in computer vision. Divided into 10,000 test pictures and 50,000 training images, CIFAR-10[2] is a rigorous method of assessing model performance. It consists of 60,000 color images with a pixel size of 32×32. The set’s images are hand-labeled into 10 mutually exclusive classes: trucks, cars, frogs, horses, birds, dogs, cats, deer, aircraft, and cars. Because these classes cover a wide range of object categories, CIFAR-10 [2]is a good tool for evaluating how effectively models generalize across different visual attributes.
One of CIFAR-10’s intriguing aspects is its very low picture resolution, which pushes models to extract pertinent features from a small number of pixels. This affects feature extraction capacity rather than high resolution (HR) detail gathering. Because CNNs are adept at spotting hierarchy of space in visual data, it is therefore particularly useful for assessing them. To improve sample diversity and prevent overfitting, the CIFAR-10 dataset is frequently enhanced during training using methods including cropping, horizontal flipping, and even color jittering. Additionally, the categorical character of the dataset would easily fit with the usage of probability-based classifying metrics like cross-entropy loss in networks with a softmax output layer. CIFAR-10 is a typical dataset used in machine learning research.
2.1: Explaining the code
This code implements a softmax classifier for the CIFAR-10[2] dataset using TensorFlow’s[1] version 1 framework to perform image classification. First, it imports essential libraries and modules, including numpy for numerical operations, tensorflow.compat.v1 (with v2 features disabled for compatibility with older TensorFlow code), and a helper module data_helpers for loading the CIFAR-10[2] dataset. Basic parameters like batch size, learning rate, and number of training steps (max_steps) are defined for controlling the training process. The code begins by loading the CIFAR-10 dataset through data_helpers.load_data(), storing training and test images and labels.
The TensorFlow[1] computational graph is then defined, starting with placeholders for input images and labels. Each image is flattened to a vector of 3072 values (32x32x3), and there are 10 possible classes in the CIFAR-10[2] dataset. The classifier parameters consist of weights and biases, both initialized to zero, which will be optimized during training. The logits calculation (tf.matmul(images_placeholder, weights) + biases) represents the unnormalized scores for each class. The loss function, tf.nn.sparse_softmax_cross_entropy_with_logits, calculates the softmax cross-entropy between logits and true labels, producing a mean loss over the batch. To minimize this loss, the GradientDescentOptimizer is used with the specified learning rate.
The model’s accuracy is determined by comparing predicted labels to true labels with tf.equal and averaging correct predictions over the batch. In the training loop, random mini-batches of images and labels are drawn, and the model’s accuracy is printed every 100 steps. After completing all training steps, the model’s accuracy on the test set is calculated and printed. Finally, the code measures and prints the total runtime of the script, making it easy to track the computational efficiency of the training process.
2.2: Code execution
2.2.1 Training Procedure
In training, the code employs a softmax classifier. A softmax classifier is a type of logistic regression model that is often deployed to handle multi-class classification problems. The different steps adopted during the training procedure are as follows:
Initialization of Weights: At the first step, we initialize the weights and biases for softmax classifiers (usually small random values or zeros). The weights will thus represent the “knowledge” of the model and will be set appropriately later during training for best performance
Forward pass: The model produces predictions for each input batch of images by taking the sum of the weighted inputs followed by application of softmax activation for generating probabilities for each class. In other words, it’s essentially assigning a probability to each class-“dog,” “cat,” and so on in CIFAR-10[2]-for each image.
Loss Calculation: The code makes use of a loss function-a so-called cross entropy which measures how well the model’s predicted probability of the class labels compares to the actual probabilities of the class labels. The value of loss is high if there is a big difference between the predictions and the correct answers vice versa.
Backpropagation and Gradient Descent: The model calculates the gradients, which specify how the weights should be updated to minimize the loss. Then, it uses gradient descent to update the weights, analogous to the series of small steps toward reducing the error. In this code, we will use tf.train.GradientDescentOptimizer to carry out these updates. The learning rate is step size; a small learning rate brings slower learning whereas a large learning rate might induce instability.
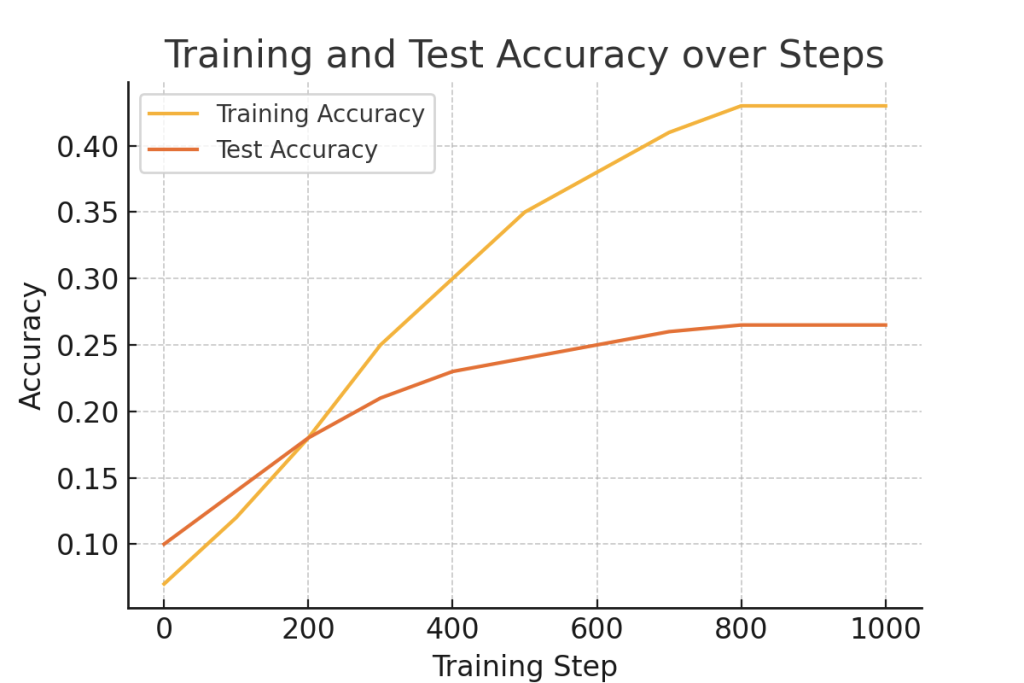
Monitoring Accuracy: The program outputs the training accuracy every 100 steps. Training accuracy is the percentage of accurate predictions on the training dataset at every step. Here’s how it goes:
Step 0: Training accuracy starts very low at 0.07 (7%), meaning the model is nearly just guessing.
This gradually increases at each step to about 0.43 (43%) at step 900, indicating it is learning, though the improvement is quite slow, which is expected of a simple softmax model on such a complex dataset.
The learning curve with respect to the increase in training accuracy is a gentle ascent as the model learns, adjusting its weights based on the training data to improve class label predictions. However, the final training accuracy is still less than 50% and hence indicates that the model is not effective enough to fit the data accurately in comparison with the complexity of the CIFAR-10 data set, perhaps because of the simplicity of the softmax model against the complexity of the CIFAR-10[2] data set.
2.2.2 Test Accuracy
After the training process, the code tests the model on the test dataset, composed of images the model has not encountered while training. Then it can figure out if the model is good at generalizing well to new data. The final test accuracy of this output is 0.265 or 26.5%, meaning the model classifies only approximately 26.5% of the images in the test correctly.
Most probably the reason for this very low test accuracy is
Model Simplicity: A softmax classifier is a fairly simple linear model, though it really works fine for linearly separable data. However, it does not work well when the patterns become more complex. The CIFAR-10 collection contains 10 diverse categories of low-resolution images that require more advanced feature extraction.
Overfitting Risk: Although this result does not indicate overfitting, if the training accuracy were much higher than the test accuracy, that would indicate that the model is overfitting (memorizing training data instead of generalizing). In the present case, both training and test accuracies are low, and this could indicate underfitting-the model hasn’t captured enough of the data patterns.
More complex models than a softmax classifier, for example, CNNs, are often required to handle spatial patterns in the case of CIFAR-10 and deliver better performance.
2.2.3 Execution Time
The execution time shown here is 5.77 seconds, which represents the time taken by this model to train and evaluate completely on the CPU. Here are some reasons for this time:
Model Complexity: A softmax classifier has relatively little complexity; therefore, the computation needs are less compared with a complex model like CNN or deep neural nets. This moderate complexity keeps the training short in time.
The code emits a warning that it doesn’t use certain CPU features (like AVX2, AVX) that could accelerate the processing. Meaning, the code could possibly have run faster if TensorFlow[1] had been optimized for the available hardware. But even without any such optimizations, the lightweight model finishes training fast.
Batch Size and Number of Steps: Because the size of the data processed per step and the number of steps (in this case, 1000) also determine execution time, a large number of them may be converged much faster but demand more memory. Small batch sizes make the training much slower but more stable.
It has an advantage in short training times for speed experiments but suffers at the expense of lower accuracy on such a complex dataset like CIFAR-10.

3. Discussion
Overall, submerging myself into the world of image classification has been an extremely enlightening, exciting, and complex experience. The journey started with understanding some basics in this field- what image classification was and how it all works behind the scenes. Essentially, teaching a computer to recognize and categorize images based on the various classes it belongs in, is made up of a good deal of programming, mathematics, and a good amount of machine learning.
This was going to take me into the rather complex process of compiler building, ensuring that the code is run efficiently and supports the different operations needed in activities such as image classification. It was observed that one needs to work with a variety of data-sets to understand which ones train the model and which ones are for testing and how it all impacts on the resulting accuracy or applicability of the model.
The other aspect of this journey involved learning how to load and preprocess data correctly. Handling datasets gets pretty complex at times, but I learned how to streamline the process so that my workflow is really smooth. It was after this foundation that The challenge was undertaken to of developing my own image classifier.
It was an experience with rich challenges and rewards building the image classifier from scratch. This required foundational concepts and how to apply them in practice. This process demonstrated to be methodical about solving problems, think critically, especially when debugging issues, exploring different architectures, and fine-tuning my model, and this is what gave me the great feeling of the first time that my model started making correct predictions.
This study has yielded significant insights as part of my learning journey. This study provided deeper insights into machine learning and programming, and this has made me feel even stronger about the complexity of problems in technology. Future work will focus on building on this platform and diversifying further into more profound concepts, and not merely applying the gained knowledge to real-world problems. The prospects are endless, and It is anticipated that where this journey will take me.
Mastering the art of image classification was, in no way, smooth-sailing. It was necessary to spend a lot of time to grasp the concepts and mechanics underlying it. The process begins with developing a softmax classifier, guided by a tutorial from a website. This is a pretty straightforward stage, though it started the ball rolling in understanding the true nature of the process and establishing a basis for an eventual good performance.
Significant changes occurred when when An attempt was made to build my own image classifier. The task was both complex and engaging but also at times overwhelming and demanding. The most difficult part was having to integrate the CIFAR-10 dataset with custom labels. That really put me in extreme conditions and tested all my problem-solving skills.
Although there were some hitches here and there, struggle seemed worth every moment because it was very rewarding to overcome the obstacles; learning something which I had always wanted to learn made the experience worthwhile. Some aspects, such as the softmax classifier, were easier to handle, but as a whole, the process taught me how resilient and adaptable I could be and continues to sustain my passion to dig deeper into such topics.
Conclusion
This paper in detail describes what steps occur to develop and apply a softmax classifier for image classification work, using the CIFAR-10 dataset. Image classification is one of the main applications of neural networks, translating visual data into actionable insights. It plays a massive role in industries such as healthcare, security, and autonomous systems, so improving decision-making and operational efficiency requires its effectiveness.
At the same time, it begins from the very start with the fundamental concepts of image classification, basically understanding visual data. Deep learning models, like CNN, are significant contenders in advancements in image classification. CNNs can detect spatial hierarchies in images starting from low-level features, such as edges, going into a complex structure, such as objects. Vision transformers, or ViTs, are an emerging technique using a self-attention mechanism for capturing global context, sometimes even outperforming CNNs when applied to large datasets.
CIFAR-10 is the benchmark dataset for models used in image classification. It comprises 60,000 images at low resolution, divided across 10 mutually exclusive classes: airplanes, cars, animals, grouped into 50,000 training and 10,000 test images. Low-resolution data sets make it hard for the model to draw meaningful features from small visual data sets. Often, data augmentation techniques like cropping, flipping, or color jittering are applied to add diversity in the training process and counter overfitting.
The softmax classifier is an integral component of this image classification framework: the outputs of the neural network are converted into probability distributions of multiple classes. Here, the softmax function normalizes those outputs so that the sum of the probabilities of all classes equals one, making it likely to be a class for each input. At training time, this classifier measures the difference between predicted and actual probabilities with cross-entropy loss functions and iteratively adjusts weights to be able to increase accuracy of the decision.
All of the softmax classifier code is written completely structured with TensorFlow. It includes the initialization of weights and biases, forward pass to produce class probabilities, computing loss, and updating the weight using gradient descent. In training the model, batches of images are pushed forward while monitoring accuracy at intervals and continuously refining the weights. Even though this method has many complexities to it, this is the core method from which one gets foundational insights into image classification workflows.
This can be considered a case of the softmax classifier on the CIFAR-10 dataset; however, there are immense limitations toward this model. A model-wise perspective shows how, by 1,000 training steps, it represented an accuracy of 43% on the training and only 26.5% on the test. These figures mark indicators that the model failed to incorporate the complexity this dataset may feature, considering its linearly based approach. Well-suited for some simpler tasks, the softmax classifier cannot handle those datasets requiring much more advanced feature extraction.
The challenges faced in the process of this project were underfitting – which is when the models fail to generalize patterns-and then custom labels to add on dataset difficulties. These really highlighted the idea of further complex models like CNN, which is further superior for dealing with any type of complex data. Moreover, the images of CIFAR-10 are at a lower resolution, making it more challenging, forcing the model to extract relevant feature from the limited pixel space.
The project addressed issues of ethical and computational challenges in image recognition. Issues ranged from algorithmic bias, privacy concerns, to the need for a large quantity of labeled data and computational powers. Some of these issues are reflected in the highlighted point that illustrates the need for developing scalable, bias-free algorithms applicable in real-world applications.
Despite these restrictions, this project provided some very valuable learning opportunities. This experience of building and testing a softmax classifier brings insight into many real-world aspects of image classification. It brought up the importance of iterative optimization, the difficulty of dealing with complex datasets, and the promise more advanced techniques hold in bettering accuracy.
Future work in image classification could include use of semi-supervised and unsupervised learning to decrease dependencies of training data. Techniques such as GANs can be used to produce synthetic training data and thus eliminate the problem of scarcity of available data. In addition, integrating CNNs or more advanced architectures for such architectures as vision transformers may further enhance performance for data sets like CIFAR-10.
Conclusion This project is at once a learning experience and a stepping stone into further research in the areas of computer vision. There being limitations to such simpler models that exist and having found ways to upgrade those opens the doors to more robust and effective image-classification solutions. Lessons learned here don’t go beyond academic lines but already carry high applicability in practice in medical care, autonomous systems, or security industries that work with visual data analysis.
| Metric | Value | Dataset | Notes |
| Training Accuracy | 43% | Training Set | After 1000 steps |
| Test Accuracy | 26.5% | Test Set | Indicates underfitting |
| Execution Time | 5.77 seconds | Full Process | On CPU, unoptimized |
Citations
[1] https://www.tensorflow.org/tutorials/images/classification
[2]https://www.cs.toronto.edu/~kriz/cifar.html
[3]https://www.tandfonline.com/doi/full/10.1080/01431160600746456
[4]https://ieeexplore.ieee.org/abstract/document/4309314
[5]https://www.superannotate.com/blog/image-classification-basics
[6]https://viso.ai/computer-vision/image-classification/
[7]https://www.tensorflow.org/tutorials
[8]https://pyimagesearch.com/2016/09/12/softmax-classifiers-explained/
About the author
Sarikonda Grishmanth Reddy
Sarikonda is an enthusiastic computer science student with a special interest in artificial intelligence, machine learning, and image classification. His academic path so far has been driven by an interest to discover new technologies and pursue a practical approach toward solving problems in real life. Beyond academics, Sarikonda heads the boys’ hostel in his college as a Head Boy, and this has been honed to develop leadership and organizational skills. He also participates in planning and executing various social and charitable events, which has given him an opportunity to believe in the sentiments of community and serve society.