
Author: Srikrishna Ammu
Boston University
Mentor: Dr. Apoorva Bhandari
Introduction
The field of science uses observations from the natural world to comprehend the explanations and procedures behind every event. This perspective implies the interconnectedness between psychology and neuroscience. While psychology focuses on numerous unique mental processes and human behaviors from various subfields, such as cognition and development, neuroscience aims to record the complex communication and activity occurring throughout the brain and nervous system that is vital to produce certain behavioral phenomena. The action or behavior in particular that I will further investigate with reference to the described domains is reinforcement learning. One way to think about reinforcement learning is that it helps to understand that we continue to implement the same choice or shift towards another based on varied outcomes or rewards. In other words, the consequences of each trial could alter our predictions and decision-making. Computational models of reinforcement learning are developed, simulated, and fitted into real-world data to test hypotheses of cognition. A multitude of activity occurs in many corners of the nervous system that needs to be deciphered to describe the findings about each area of the brain and how they are interdependent with reinforcement learning. Two essential foundations that can help us further perceive reinforcement learning is classical and operant/instrumental conditioning.
Psychology of Reinforcement Learning
Classical Conditioning
A neutral stimulus is an event that does not reveal a specific response, while an unconditioned stimulus (US) results in an automatic reply known as the unconditioned response (UR). Suppose the transition from the neutral to the unconditioned occurs multiple times, and the two stimuli are associated or easily predicted in the agent’s mind. In that case, it will produce the same response as the unconditioned called the conditioned response (CR) for the neutral stimulus. Therefore, the neutral stimulus is now referred to as a conditioned stimulus (CS) (Rehman, Mahabadi, Sanvictores, & Rehman, 2022). Key terminologies are integral to further recognizing the behaviors involved in classical conditioning. Giving the same CR to things the subject perceives as similar to the CS is known as stimulus generalization. In contrast, stimulus discrimination is when the participant is aware of the differences between the conditioned and other stimuli and responds to each separately. If the US less frequently appears after the conditioned, the CR is slowly removed within our system; this is defined as extinction . However, if the US is suddenly presented after CS, that specific classical conditioning scenario is reactivated; this describes spontaneous recovery (Rehman, Mahabadi, Sanvictores, & Rehman, 2022). Studies that have contributed to understanding this form of learning are Pavlov’s work and the Little Albert Experiment. Classical conditioning directs our awareness of the role of predictions in reinforcement learning.
Operant Conditioning
The effects of certain activities can improve or build new behaviors by guiding agents towards redoing an action or slowly avoiding it. There are a couple of paths to dive into, so one can further grasp the details of this kind of learning. The most common form of operant conditioning is positive reinforcement. This involves receiving a reward or positive reinforcer that increases the behavior recently implemented. On the other hand, negative reinforcement explains that relieving oneself from something undesired also strengthens the willingness to continue that behavior. However, positive and negative punishment describes a different process. Positive punishment is when the subject receives an additional burden, while negative punishment removes something pleasant, most likely directing them to decrease that action gradually (McLeod, 2018). It is also necessary to inform that not earning a reward after a given task has been achieved can also lead to weaker performance of that activity in the future. B.F. Skinner was a renowned psychologist during his time and even today. His theories and experiments using the operant chamber/Skinner box contributed significantly towards understanding a key component of human behavior. The study of operant conditioning relating to reinforcement learning has shown that our aim toward earning more rewards follows the development of strategies.
Reward Prediction Error and Rescorla Wagner
An integral point of reinforcement learning is that continuous implementation of a task and realizing where one can go wrong in the procedure can slowly guide us towards making decisions to get the best possible reward. Classical conditioning can help us relate to the components of reinforcement learning, from prediction errors to values. What learning in the form of behaviors and ideas arises from classical conditioning? As mentioned earlier, agents could predict that an unconditioned stimulus will come after the conditioned; therefore, they were prepared beforehand by presenting a conditioned response. Similarly, in reinforcement learning, the amount of reward anticipation can support decision-making. This ability comes through experience by observing different trials and their results (Daw & Tobler, 2014). Initially, we develop an expected value, the reward anticipated if one selected a particular option. However, it could also be zero because the subject might be doing the activity or game for the first time without experience or expectations. This leads the participant to plan and carry out decisions, and an outcome is reached, leading to the prediction error. The prediction error computes the gap between the expected value and the actual amount of reward. This is similar to Ivan Pavlov’s observations, where a dog has a high expectation of receiving a treat after the bell (the conditioned stimulus) and either receives or doesn’t, except it doesn’t make a choice unlike reinforcement learning. Prediction Error is divided into two parts: positive and negative prediction error. Prediction Error is summarized with a mathematical formula where r is the reward after choice k at trial t between 0 and 1.(Wilson & Collins, 2019)
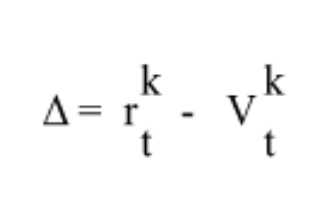
The learning rate determines the weight or how seriously the participant takes the prediction error. It is represented through the alpha parameter, α, where a quantity of 0 simplifies that regardless of how far or close the prediction error might seem, the value of a choice would be constant. However, if the learning rate is initially set to 1, the value is fully updated based on the previous outcome. Given the input of the expected value, prediction, error, and learning rate, a result is the updated value. This type of reinforcement learning is called Rescorla Wagner. Its mathematical explanation is given below, where V at t (the previous trial) is the expected value and V at t+1(the next trial) is the updated value. (Wilson & Collins, 2019)
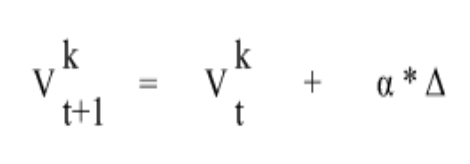
Finally, Rescorla Wagner is another kind of learning through reward by changing the values of certain options based on the result. This can guide us towards making better choices that could reach optimization.
Temporal Difference Learning
Sutton and Barto were two renowned scientists of the 20th century that developed Temporal Difference (TD) learning in response to different observations about the Rescorla Wagner Model. For example, the theory perceived that time goes through single and set periods called trials where the expected value of options is updated. It also concluded that signals could anticipate that different events could arrive. Finally, the model could also continue to compute the weight of past events or choices. However, some limitations of the Rescorla Wagner theory are essential to be aware of. It did not capture the major goal of learning processes Sutton and Barto formulated. They expressed that learning directs the value of events or selections in the future but not in the past, even though past occurrences can lead to these future values. Emphasizing future values, we should change how we approach reward prediction error. To reiterate, prediction error calculates the difference between the expected value or the average of the values of each trial from the past up to some point and the resulting reward. However, to rephrase it for this context, we should describe it as the gap between future expectations of rewards based on logic and reasoning and the predictive stimuli and reward (Glimcher, 2011). This shows that prediction error and learning can occur not only after the trial but also at the point when the predictive stimuli were present or the time before the final reward. Rescorla Wagner was also not able to explain that even though there is a strong association between a stimulus and a resulting reward, that stimulus that reappears in the future can’t help when it comes to learning new things. Another point to remember is that time is constantly moving in reality compared to trials, indicating that there could be complexity in the environment, and many different things can occur. Therefore, Sutton and Barto developed a reinforcement learning theory where there are moments that are the building blocks of one trial. Additionally, they stated that learning happens not only after the trial but also at these moments. In fact, there are expectations of reward for each moment that can be represented as values and give us a total. Predicted rewards for every moment are derived by the sum of the value of the reward of a moment and the discounted reward for each of the following moments. The discounted reward is further broken down into the product of the value of the reward of one of the next moments and the discount parameter that decreases that value and measures the satisfaction of faster than slower rewards (Glimcher, 2011). This detail is simplified into a mathematical equation below where we assume that there are 50 moments.

γ -> discount parameter
V -> expectation of reward for 1st moment
r -> reward
A stimulus repetitively predicts a reward, but one is not perplexed about the reward because of the previous appearance of the stimulus. The reward relates not only with the value of the reward moment but also the value of the recent moments till the stimulus. In other words, the change of value due to the reward can be traced back to the moments of the stimulus. The many details above explain the overview of temporal difference learning.
Neuroscience of Reinforcement Learning
The Role of Dopamine
Psychologists Olds and Milner started an experiment to understand reward and the behaviors connected by setting electrodes into different areas of a rat’s brain. They directed the rat towards turning a lever, which led to a transfer of electricity and the action potential of many neurons. Action potential involves electrical charges passing through an axon surrounded by a neuron’s membrane. This helped the rat learn the lever procedure to reinforce it with the same or a higher reward(Schultz, 2016). The experiment gave the idea that events in the brain or nervous system play a vital role in the emphasis of reward, stimuli, and the behaviors that are influenced through it. Some parts of the brain where the electrodes were placed had dopamine neurons, which reveals the strong relationship between these cells and rewards.
Dopamine is a neurotransmitter that functions at its best when we accomplish a goal or are highly motivated. Dopamine or dopaminergic neurons have these chemicals found in the midbrain, whose axons connect parts of the brain, such as the amygdala and prefrontal cortex. The action potentials of these neurons are initiated when one receives a reward; as the reward becomes greater, the dopamine response strengthens. The dopamine response also activates when one observes stimuli that anticipate future rewards. These neurons store information about past and future rewards, guiding us when planning and making choices. It is important to note that the activity of dopamine responses during conditioned stimuli is not as much as the actual reward. Dopamine neurons can comprehend past actions through conditioned stimuli and clarify a long chain of events.
Although positive and negative reward prediction errors weren’t mentioned above, they will be defined here because of their strong relationship with dopamine responses. A positive reward prediction error is when our expectations are exceeded because of a higher reward. Dopamine responses are strengthened, which is known as positive dopamine response or activation, during this experience. On the other hand, a negative reward prediction error occurs when the resulting reward does not meet our expectations; therefore, the dopamine response is depressed or decreases. Finally, an outcome that comes as expected tells that there is no prediction error and dopamine response. One helpful idea to remember is that of Temporal Discounting, which describes that the further the time between the conditioned stimuli and reward, the weight of the reward decreases, as well as the dopamine response. Prediction errors compared with full awareness help us to understand the environment around us efficiently and save processing (Schultz, 2016).
Suppose a group of people gain a reward higher than predicted and the dopamine response is highly active, their anticipation could increase based on the resulting reward, and they would be accustomed to it. If they receive the same reward in the future, there would be no prediction error and dopamine response because of that previous update. However, if a positive prediction error (increasing rewards) dopamine response continues to occur, our desire for escalating reward improves regardless of what we have. This illustrates that dopamine activity increases when someone comes across a reward, which would bring forth new learning and behavior.
We take a look at the environment around us, including rewards, undesired results, and neutral stimuli. We try to find something that stands out, and our neurons are aware of it quickly. Once we have noticed that an object has the property of salience, this procedure known as initial nonselective response leaves very soon. The subsequent process, known as the second selective response, involves processing reward detail even before we realize it is a reward. This gives us time to approach the reward when we know about it(Schultz, 2016). The overall procedure explained in detail above is known as careful analysis. These are essential parts of a dopamine response whenever a reward, stimuli, or reward prediction error is present.
Synopsis
Using psychological terms and detail, we were able to explore reinforcement learning behavior and the important role of predictions and rewards through the perspectives of conditioning such as classical and instrumental and value learning such as rescorla-wagner and temporal difference. Mathematical equations were also included to illustrate and summarize the detailed learning processes; therefore, the field of mathematics is also another interdisciplinary pathway to understand different behavioral and cognitive processes. We also reviewed experiments that created the foundation and realization that biological and neurological processes place an important role in scientifically observable behaviors, especially of that related to reward. The action potential of dopamine neurons and dopamine response surges when one comes across anticipations and reward is another component that we looked into detail about. This relates to the summer project I did that dealt with building computational models and analyzing the parameters that best fit the data, which helps formulate and test cognitive and reinforcement learning processes. The combination of findings based on the research paper and computational modeling exercises establishes the intricate and profound connectivity between psychology and neuroscience when it comes to understanding reinforcement learning.
References
Rehman, I., & Mahabadi, N., & Sanvictores, T., & Rehman, C. (2022). Classical Conditioning. Retrieved from National Center for Biotechnology Information.
McLeod, S. (2018). Skinner – Operant Conditioning. Retrieved from Simply Psychology.
Daw, N., & Tobler, P. (2014). Chapter 15 – Value Learning through Reinforcement: The Basics of Dopamine and Reinforcement Learning. Retrieved from ScienceDirect.
Wilson, R., & Collins, A. (2019). Ten simple rules for the computational modeling of behavioral data. Retrieved from eLife.
Glimcher, P. (2011). Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis. Retrieved from Proceedings of the National Academy of Sciences.
Schultz, W. (2016). Dopamine reward prediction error coding. Retrieved from PubMed Central.
About the author

Srikrishna Ammu
Srikrishna Ammu is currently a first-year student at Boston University majoring in Neuroscience. He is interested in studying the field to discover the biological processes behind human behavioral phenomena and to create strong connections with related fields such as Chemistry and Artificial Intelligence. Krishna also reads different scientific articles to learn about the latest advancements in Neuroscience and Medicine. He worked on a research project that involved utilizing Matlab software to investigate reinforcement learning further. His hobbies include playing tennis, chess, and the piano, and he volunteers at a hospital during his free time to explore the medical field.